AI-first, not AI-only
AI generates code. Senior experts own the process. You get production systems.
T1K = Tänk Tusen
Before you can scale to production, you must think first.
One person delivering value to a thousand customers isn't magic — it's the result of thinking ahead: How does this work at scale? What breaks at 1,000 users? Where are the bottlenecks?
You have to drown in data before you can structure it.
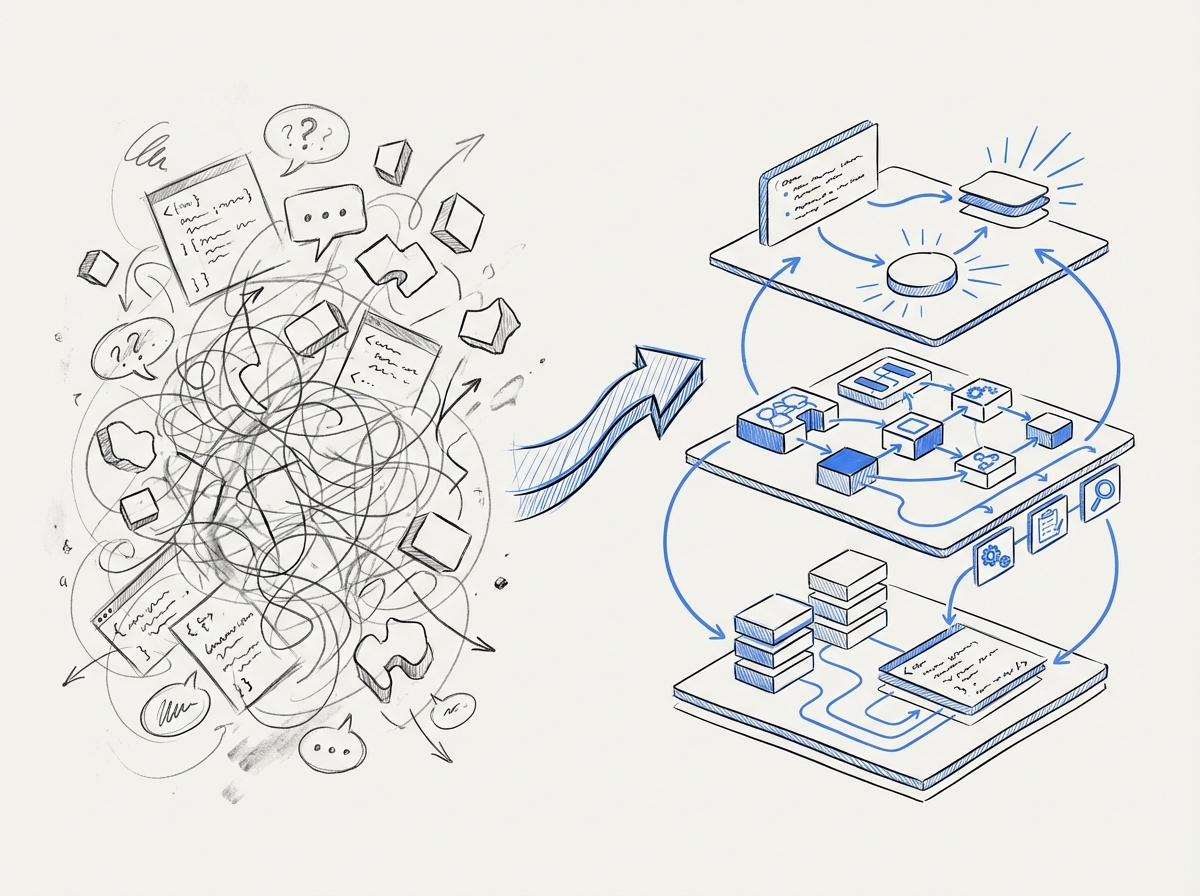
How we work
Voice to requirements
Tell us what you need — in a normal conversation, not a document. Voice captures tone, intention, and unspoken requirements that written specs miss. AI analyzes and structures into production-ready requirements. Same principle regardless of domain: from a 3-minute voice recording to an AI chatbot for healthcare, or a 15-minute phone call to a complete website (behindbars.se).
AI generation
AI generates code based on requirements. 500+ iterations of refinement deliver optimal results.
Process ownership
Experienced developers own the process, steer AI generation, and take responsibility for production-ready code.
Production
Deployment to your environment or our infrastructure. Databases, security, scaling — all included.
Output as a Service
OaaS means you pay for delivered results — not consultant hours. The market is moving: established consultancies are abandoning hourly billing in favor of results-based models. T1K was built on this principle from day one.
Where others offer a simple monthly fee, T1K implements four distinct OaaS models — fixed price, SaaS subscription, revenue sharing, and idea sharing — each adapted to the customer's situation and the value created. It's not a pricing model. It's a business philosophy.
The industry calls it a paradigm shift. We call it our business model since day one.
Our infrastructure
We own the entire stack. No dependency on third-party services.
Technical infrastructure
- Local GPU — Dedicated blade servers for AI models without external dependencies
- LLM Server — Central processing with 512 GB memory per node for all AI services
- Swedish hosting — Own servers in Sweden, mirrored storage — GDPR-compliant data handling
- Own deployment — Full control over production with LXE containers for customer isolation
Methodological infrastructure
- 14 production skills — Reusable skills distributed via git — inherited architecture
- "Simple language" — Documentation everyone understands
- 500+ iterations — Proven refinement process
- Templates & use cases — Code templates and deployable examples for quick start
- Automatic documentation — Changelog in real-time
- Daily decisions — Fast feedback loop
Dive deeper into the methodology
Our documentation describes the AI-first approach in detail.
Read the documentation