AI-analysverktyg för leveransflöden
Röstbaserad specifikation till prototyp på en månad
En managementkonsultfirma inom IT-styrning behövde ett verktyg för att analysera leveransflöden hos sina kunder. Traditionell utveckling hade tagit ett år. Vi levererade en fungerande prototyp på en månad — utan ett enda kravdokument.
Utmaningen
Konsultfirman hade en tydlig vision: hjälpa sina kunder förstå var arbete fastnar i organisationen. Men att omsätta den visionen till ett fungerande verktyg innebar flera hinder.
Traditionell kravspecifikation passar inte domänexperter. De vet vad de vill se, men att formulera det i tekniska dokument tar veckor och resulterar ofta i missförstånd. När specen väl är klar har behoven förändrats.
BI-verktyg kräver ren data först. Innan man kan visualisera något måste data tvättas, struktureras och valideras. Det projektet i sig tar månader.
Beslutsfattare förstår inte tekniska dashboards. Även om verktyget byggs rätt behöver slutprodukten vara så enkel att en chef kan agera på den utan teknisk bakgrund.
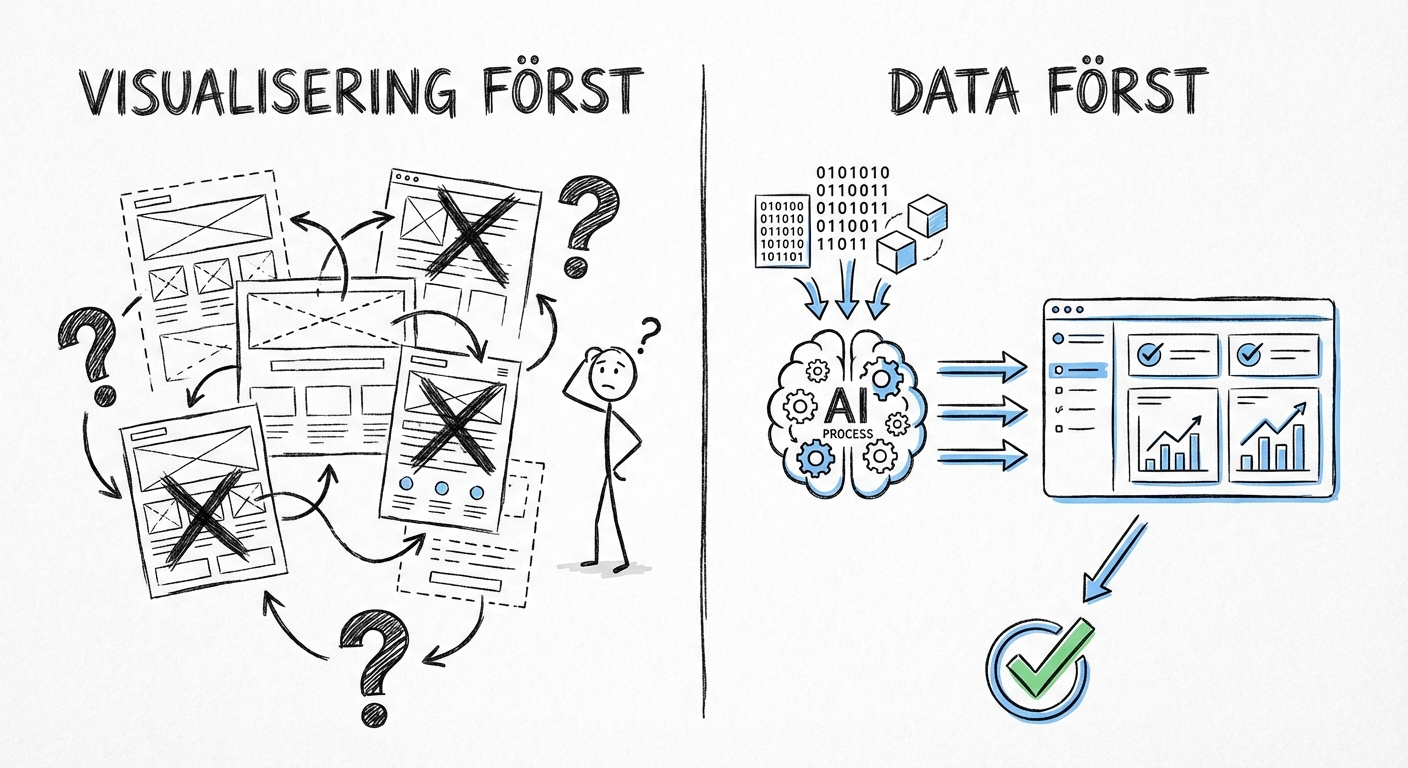
Varför inte börja med visualiseringen?
Det finns verktyg som Lovable och liknande där man börjar med att designa gränssnittet. Rita upp hur dashboarden ska se ut, definiera vilka grafer som ska finnas, bestäm layout. Sedan fyller man på med data.
Det låter intuitivt — men det fungerar sällan för analysverktyg.
Problemet med visualisering först:
Utan data vet man inte vad som är intressant. Konsulterna hade idéer om vad de ville se — "var arbete fastnar" — men de visste inte hur det skulle visualiseras förrän de såg verklig data. Vilka mönster finns? Vilka avvikelser är relevanta? Det går inte att rita en graf för något man inte har sett.
Mockups skapar falska förväntningar. En snygg skiss med påhittad data ser bra ut i presentationer. Men när verklig data laddas in stämmer inget. Skalor blir fel, kategorier saknas, mönster syns inte. Iterationen börjar om från noll.
BI-projekt som börjar med visualisering fastnar i datakurering. "Den här grafen kräver att datat ser ut så här." Veckor går åt till att tvätta, strukturera och anpassa data till en förutbestämd design. Om designen var fel från början — vilket den ofta är — har man slösat månader.
Data först vänder på logiken:
Vi börjar med vad som finns, inte med vad vi tror ska finnas. AI tolkar datat semantiskt och föreslår vad som är intressant. Visualiseringen växer fram ur vad datat faktiskt visar. Ingen tid slösas på att kurrera data till en design som sedan måste ändras.
Arbetsprocessen
Vi använde en helt annan approach — en som utgår från hur domänexperter faktiskt tänker och kommunicerar.
Steg 1: Röstinspelning av krav
Istället för att skriva dokument spelade konsulterna in sina tankar muntligt. Vi kallar det "svamla" — medvetet ostrukturerat, verbalt, med alla nyanser och osäkerheter intakta.
Ett typiskt inspelat segment kunde låta så här: "Vi vill kunna se var arbete fastnar... alltså, det handlar om att förstå flödet genom organisationen... ibland stannar saker i review för länge, ibland är det prioriteringar som ändras mitt i... och sen är det det här med att folk jobbar på för många saker samtidigt..."
Ju mer kontext, desto bättre. Tvekan, omformuleringar och sidospår är värdefulla — de avslöjar komplexitet som ett polerat kravdokument hade dolt.
Steg 2: AI bearbetar och ställer följdfrågor
Inspelningen transkriberades och analyserades. AI:n genererade specifika följdfrågor baserat på oklarheter och antaganden:
- "Vad menar ni med 'fastnar' — att ärenden står i samma status länge, eller att de bollas fram och tillbaka?"
- "Vilka statusar i projekthanteringssystemet signalerar väntan vs aktivt arbete?"
- "Hur definierar ni 'för lång tid' — finns det olika förväntningar för olika ärendetyper?"
- "När ni säger 'för många saker samtidigt' — tittar ni på individnivå, teamnivå eller båda?"
Konsulterna svarade muntligt igen. Varje svar genererade nya, mer specifika frågor. Efter tre-fyra rundor hade vi en implicit specifikation som fångade vad de faktiskt menade — inte vad de trodde att de behövde skriva.
Steg 3: Data laddas in utan kurering
Vi hämtade rådata direkt från kundens projekthanteringssystem — tusentals ärenden med historik, statusövergångar och metadata. Ingen tvättning, ingen strukturering i förväg.
AI tolkade datat semantiskt: "Det här fältet verkar beskriva ärendetyp, även om det heter olika saker i olika projekt." "De här tre statusarna verkar alla betyda 'väntar på någon annan'." "Det finns ett mönster där ärenden ofta går tillbaka från 'review' till 'in progress'."
Tolkningarna presenterades för validering: "Stämmer det att 'Blocked' och 'Waiting for info' båda betyder extern blockering?" Konsulterna bekräftade eller korrigerade. Kontexten byggdes upp iterativt.
Steg 4: Prototyp på dagar
Första visualiseringen var klar inom dagar, inte månader. Inte en mockup med påhittad data — en fungerande prototyp med kundens verkliga ärenden.
Dashboarden visade: genomsnittlig cykeltid per ärendetyp, andel ärenden som flyttas mellan sprintar, var i flödet ärenden stannade längst, kopplingar mellan ärenden som AI identifierat semantiskt.
Siffrorna var verkliga. Mönstren var synliga. Problemen gick inte längre att ignorera.
Steg 5: Iteration baserad på feedback
Konsulterna såg resultatet och gav omedelbar feedback:
"Den här metriken förstår inte våra kunder — kan vi visa det enklare?" "Varför är den där stapeln röd? Vad är gränsvärdet?" "Kan vi se samma data men uppdelat per team?" "Det där diagrammet är för komplext — våra chefer kommer inte förstå det."
Vi justerade och körde igen. Varje iteration tog timmar, inte veckor. Efter tre-fyra rundor hade visualiseringen landat i något som både var tekniskt korrekt och kommunicerade tydligt till beslutsfattare.
Steg 6: Live-iteration under möte
Iterationerna blev snabbare med tiden. Under ett produktgenomgångsmöte identifierade konsulterna tre problem i dashboarden: en graf med överlappande intervall på X-axeln, en annan graf vars datumintervall inte matchade valt filter, och en tredje vy som visade avslutade ärenden bland aktiva friktionszoner. Alla tre åtgärdades under pågående möte — totalt cirka fem minuter. Konsulterna estimerade efteråt att samma jobb hade tagit en halv arbetsdag med traditionell utveckling.
Det här är inte magi utan en strukturerad pipeline. Varje ändring följer samma steg: läsa in kodbasen, skapa en change request med tydlig avgränsning, beräkna en confidence score som anger sannolikheten att ändringen inte påverkar andra delar av systemet, brancha ut, implementera, uppdatera changelog och dokumentation, checka tillbaka och produktionssätta. Samma steg som en disciplinerad utvecklare gör — bara att AI utför det tunga arbetet medan den seniora utvecklaren äger varje beslut.
En av konsulterna sammanfattade det efteråt: "Det där var mitt jobb i många år. Det är basic-grejer, ingen avancerad logik. Jag hade lätt estimerat det till en dag." Den uppskattade totala utvecklingstiden för en nyligen genomförd feature-batch var 15 dagar med traditionell utveckling. AI-orkestrerat tog det en dag.
Hastigheten förändrar arbetsprocessen fundamentalt. Frågan är inte längre "ska vi vänta till nästa sprint?" utan "ska vi bara göra det nu?". Men hastigheten förändrar inte ansvaret. Skulle ändringen vara kritisk — påverka säkerhet, data eller kärnlogik — hade utvecklaren suttit och granskat varje rad. Confidence scoring avgör den avvägningen: hög score tillåter snabb implementation, låg score kräver manuell granskning. Människan bestämmer alltid.
Designprinciper
Under arbetet kristalliserades tre principer som vi nu tillämpar generellt.
"Femåringsnivå" för beslutsfattare. Visualiseringen måste vara så enkel att en chef kan förstå den utan förklaring. Röd betyder dåligt, grönt betyder bra. Inga komplexa beräkningar synliga.
Tröskelvärden per organisation. Vad som är "bra" eller "dåligt" varierar mellan organisationer. 50% eftersläpning kan vara acceptabelt för en verksamhet men katastrofalt för en annan. Systemet måste kunna konfigureras.
Semantisk tolkning av data. Istället för att kräva att kunden strukturerar sin data på ett visst sätt tolkar AI datat som det är. Olika projekthanteringssystem, olika arbetsflöden, olika terminologi — systemet anpassar sig.
Resultat
Prototypen var redo för demo inför kundens branschnätverk inom två veckor från första samtalet. Ingen traditionell specifikation hade skrivits. Ingen data hade kurats i förväg. Konsulterna itererade på verkligt resultat istället för på papper.
Skillnaden mot traditionell utveckling är fundamental. Vi börjar inte med vad vi ska bygga — vi börjar med vad vi vill se. Data och visualisering kommer före arkitektur och specifikationer. Iterationen sker på fungerande kod, inte på dokument.
Det här är hur vi bygger.